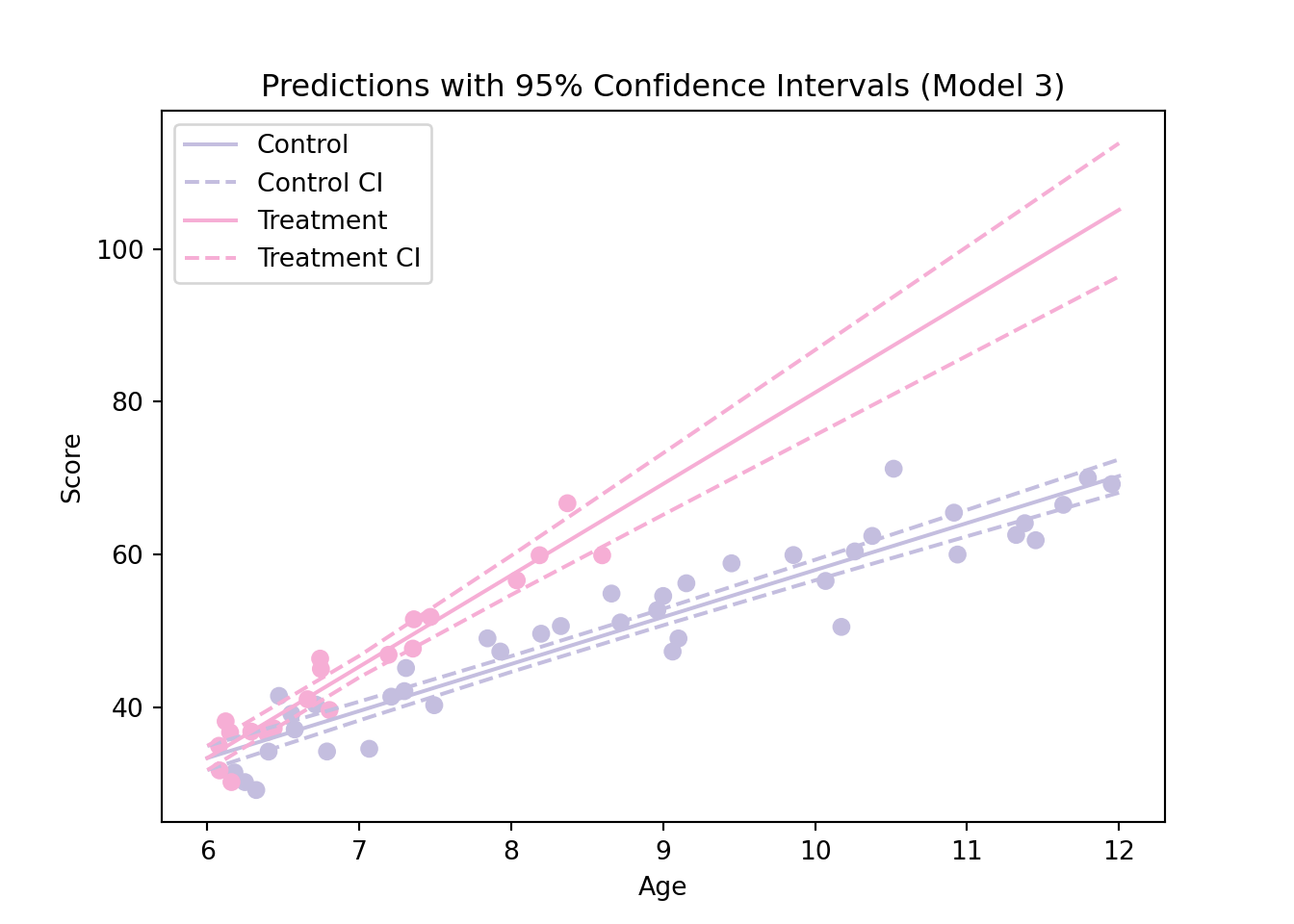
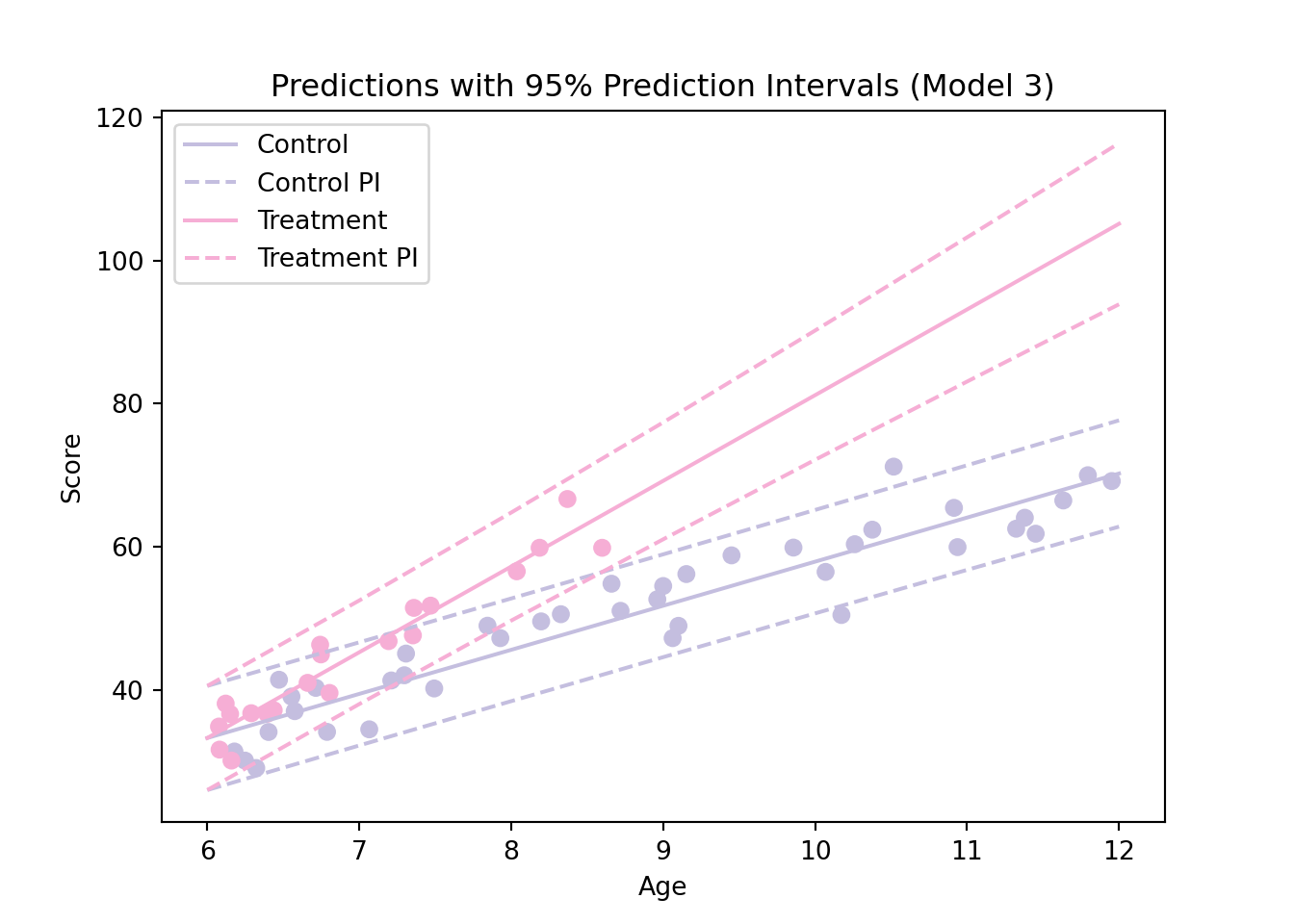
Example reading data: confidence intervals for predictions
In the previous section, we saw that the third model appears to be the most adequate among all three models we have considered. The prediction for this model can be expressed as follows:
\[
\text { Prediction Score }_i=33.3504+6.1522\left(\text { Age }_i-6\right)+5.8103 \text { Group }_i\left(\text { Age }_i-6\right)
\]
which corresponds to the expected (or average) score for a child of a certain age in a certain group. But how certain are we about this expected score? To answer this question, we can compute confidence intervals (typically at the 95% confidence level) for our predicted scores. This can be done very similarly to what we did before using the method get_prediction().summary_frame(). First, we recall how the third model is estimated:
import pandas as pdimport matplotlib.pyplot as pltimport statsmodels.formula.api as smfimport numpy as npfrom statsmodels.sandbox.regression.predstd import wls_prediction_stdreading = pd.read_csv("https://raw.githubusercontent.com/ELSTE-Master/Data-Science/main/Data/reading.csv")reading["age_minus_6"] = reading["age"] -6mod3 = smf.ols("score ~ age_minus_6 + group:age_minus_6", data=reading).fit()print(mod3.summary())
Suppose we wish to construct the predictions for children of age 6 to 12 in the control group. In the previous slides we saw that this could be done as follows:
# --- Define ages to predict (0:6 corresponds to ages 6 to 12) ---age_to_predict = np.arange(0, 7)data_control = pd.DataFrame({"age_minus_6": age_to_predict, "group": "Control"})pred_control_ci = mod3.get_prediction(data_control).summary_frame(alpha=0.05)
We can inspect the content of the pred_control_ci DataFrame to see what it contains:
The DataFrame contains the predicted mean scores (mean), the 95% confidence intervals for these means (mean_ci_lower and mean_ci_upper), and also the 95% intervals for individual observations (obs_ci_lower and obs_ci_upper). We can now repeat the same procedure for the treatment group.
Next, we extract the predicted values and the lower and upper bounds of the confidence intervals, and visualize the predictions alongside the observed data:
In some situations, it is also of interest to compute a prediction interval, which corresponds to a confidence interval for the score of a child of a certain age and group. This is different from a confidence interval for the mean. Indeed, in the previous graph we can see that many points are outside of the confidence region (which makes sense since the intervals are confidence intervals for the means). These intervals are available directly in the pred_control_ci and pred_treatment_ci objects by using the columns obs_ci_lower and obs_ci_upper.
# Extract confidence intervals for predictionspred_control_ci[['mean', 'mean_ci_lower', 'mean_ci_upper']].iloc[1]
mean 39.502667
mean_ci_lower 38.271177
mean_ci_upper 40.734158
Name: 1, dtype: float64
# Extract prediction intervals from control group age 7pred_control_ci[['mean', 'obs_ci_lower', 'obs_ci_upper']].iloc[1]
mean 39.502667
obs_ci_lower 32.304404
obs_ci_upper 46.700930
Name: 1, dtype: float64
In this output, we can see that our prediction intervals are much wider than the previous confidence intervals. For example, for a child of age 7 our predicted score is 39.50267 but the corresponding 95% prediction interval is (32.30440 46.70093). This means that with a probability of 95%, we expect the score of a child of age 7 in the control group to be somewhere between 32.30440 and 46.70093.
Naturally, we can produce a graph similarly to the one we considered previously as follows: