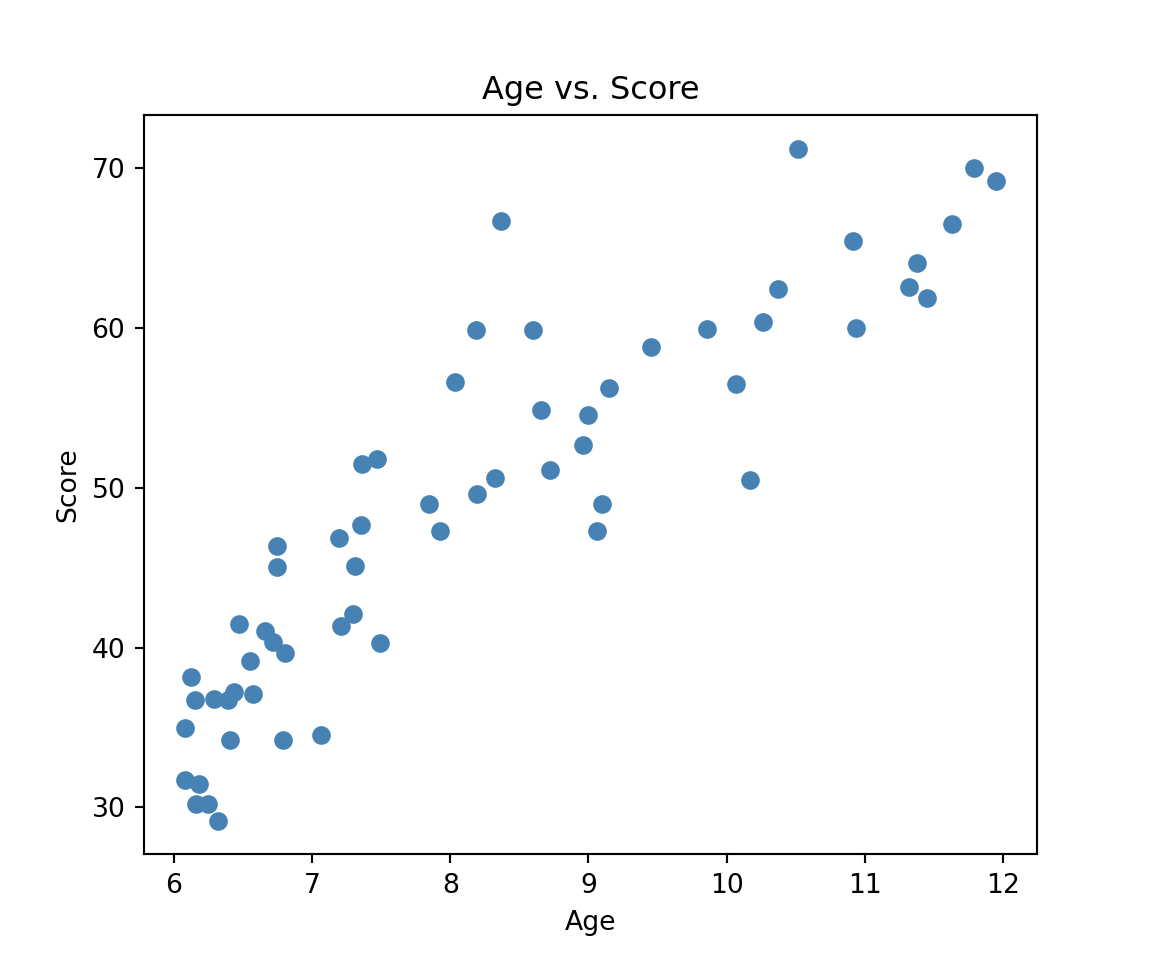
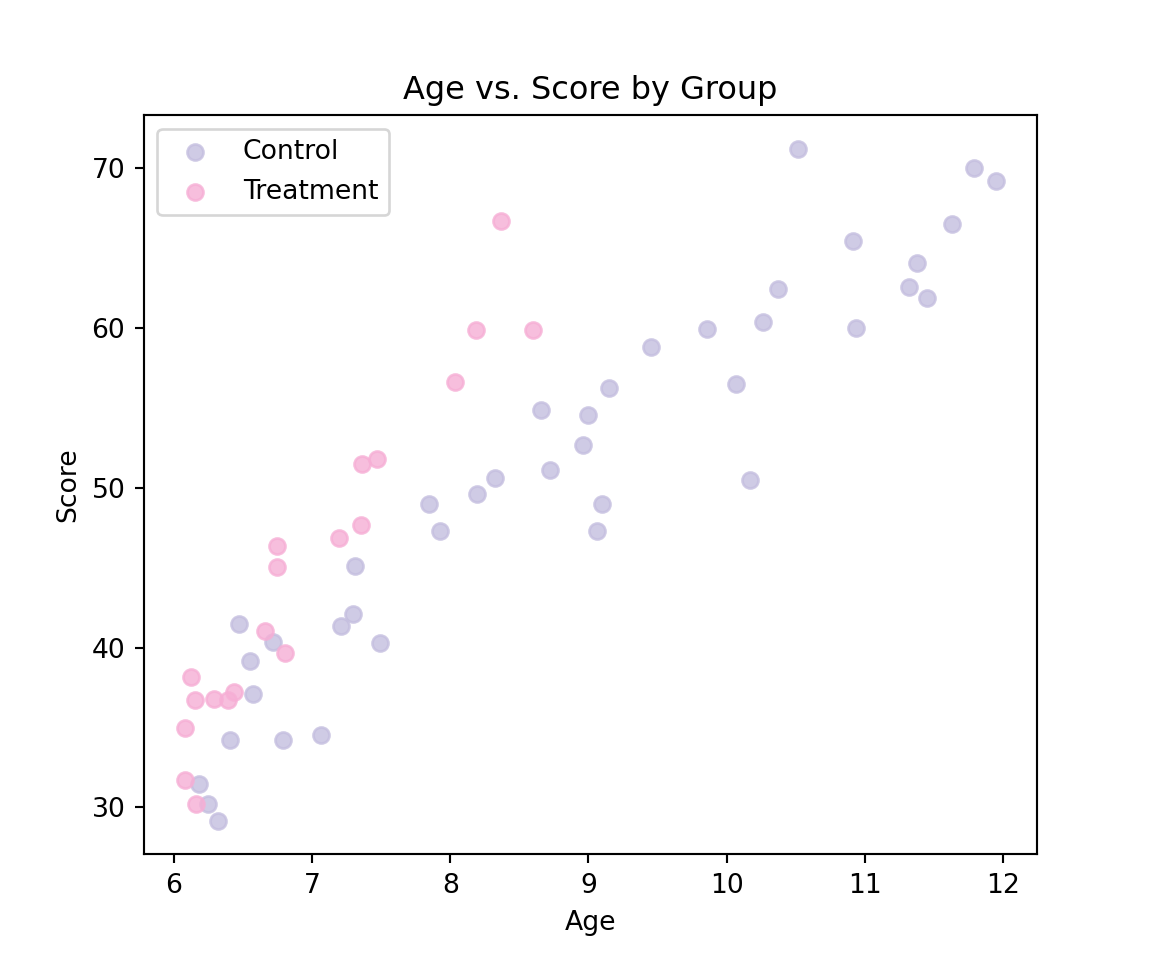
In order to assess the adequacy of our model to the data, it is useful (when this is possible) to compare the predictions and the data. This implies that we need to do two things: (1) plot the data with different colors for the groups and (2) compute predictions.
We can plot the data as follows:
import pandas as pdimport matplotlib.pyplot as pltimport statsmodels.formula.api as smfimport numpy as npreading = pd.read_csv("https://raw.githubusercontent.com/ELSTE-Master/Data-Science/main/Data/reading.csv")plt.figure(figsize=(6, 5))# Scatter plot (no color coding by group)plt.scatter(reading['age'], reading['score'], color='steelblue')# Labels and titleplt.xlabel('Age')plt.ylabel('Score')plt.title('Age vs. Score')plt.show()
Next, we will highlight the different groups using two colors.
import matplotlib.pyplot as plt# Define custom colors for each groupcolors = {'Control': '#c4bedf','Treatment': '#f6aed5'}plt.figure(figsize=(6, 5))# Scatter plot by group with specific colorsfor g in reading['group'].unique(): subset = reading[reading['group'] == g] plt.scatter(subset['age'], subset['score'], label=g, color=colors[g], alpha=0.8)# Labels and legendplt.xlabel('Age')plt.ylabel('Score')plt.title('Age vs. Score by Group')plt.legend()plt.show()
# Fit the linear model: score ~ group + agemod1 = smf.ols('score ~ group + age', data=reading).fit()print(mod1.summary())
We can now compute predictions from our model. It can be observed that the age of the children ranges from 6 to 12 so our first step is to construct a sequence of numbers from 6 to 12 as follows:
b0 = mod1.params['Intercept']b_age = mod1.params['age']b_group = mod1.params.get('group[T.Treatment]', 0) # Treatment effect# Predictions for Control group (no group effect)prediction_control = b0 + b_age * age_to_predictprint(prediction_control)
This approach provides the same results but is more reliable. Similarly, we can compute the predictions for the other groups as follows:
# Data to predict for Treatment groupdata_to_predict_treatment = pd.DataFrame({'age': age_to_predict,'group': ['Treatment'] *len(age_to_predict)})prediction_treatment = mod1.predict(data_to_predict_treatment)print(prediction_treatment)
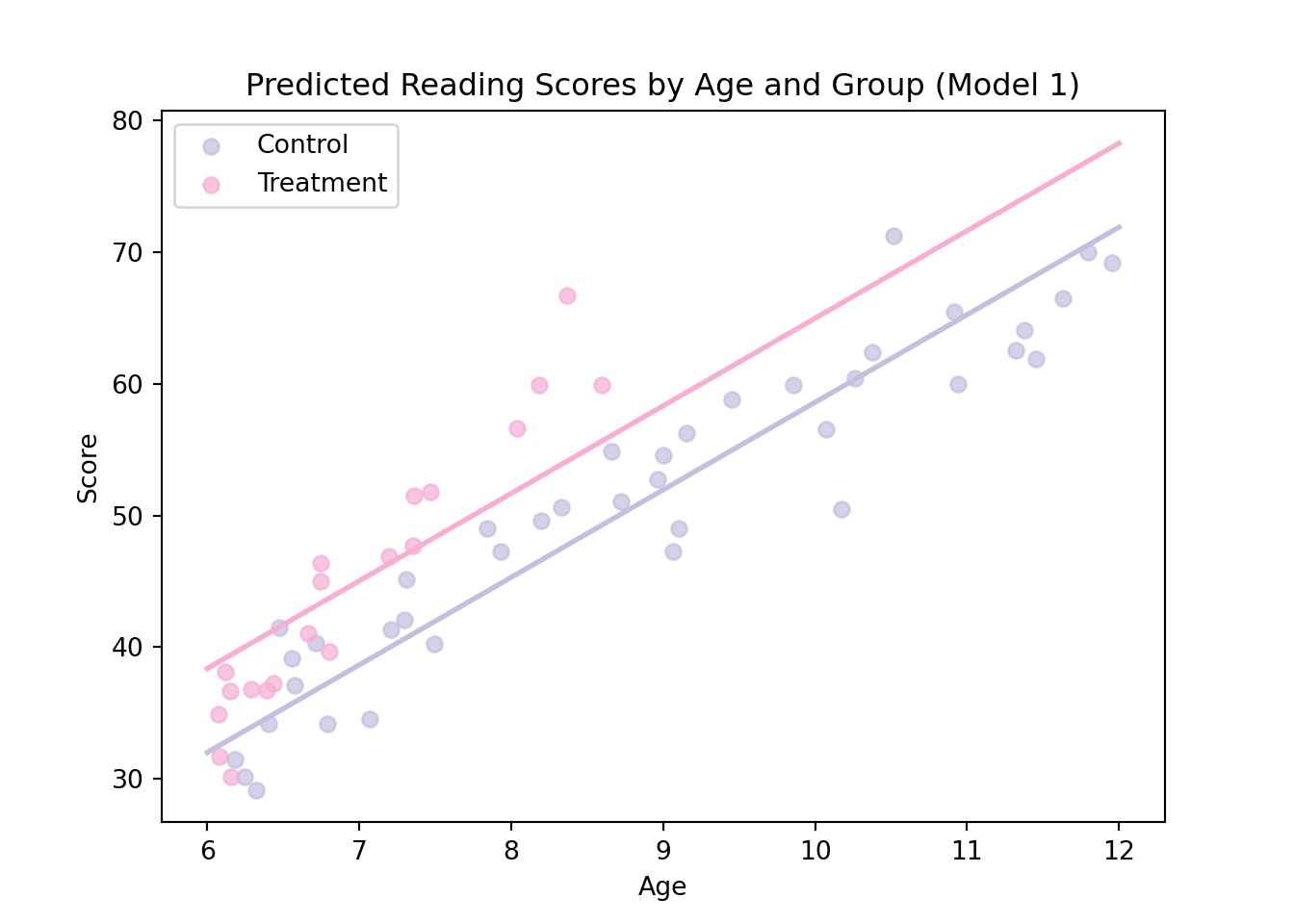
Now, we can add our predictions to the graph as follows:
# Define colorscolors = {'Control': '#c4bedf','Treatment': '#f6aed5'}# Plot observed dataplt.figure(figsize=(7, 5))for g in reading['group'].unique(): subset = reading[reading['group'] == g] plt.scatter(subset['age'], subset['score'], color=colors[g], label=g, alpha=0.7)# Add prediction linesplt.plot(age_to_predict, prediction_control, color=colors['Control'], linewidth=2)plt.plot(age_to_predict, prediction_treatment, color=colors['Treatment'], linewidth=2)# Labels and legendplt.xlabel("Age")plt.ylabel("Score")plt.title("Predicted Reading Scores by Age and Group (Model 1)")plt.legend()plt.show()
As discussed in the lecture slides, the adequacy between our predictions and the data is not ideal. To highlight the limitations of this model we will consider model diagnostic graphs in the next section.